Your AI Coworker Should Be Boring (RPA Was Right All Along)
I’ve been trying to use the Comet agent almost every day.
Partly because it’s fun, partly because I really want the “personal AI assistant” dream to be real. I open the sidebar, enter a simple prompt, and watch it start clicking around while i'm off browsing something else.
And every week there’s a new twist on the same idea:
"Meet your AI coworker for
Coworker for finance. Coworker for ops. Coworker for your inbox. A coworker that "lives in your browser" and “just does the work.”
This pitch: an AI "employee" that works 24/7, adapts to your tools, remembers your context, and costs less than an intern.
It’s the enterprise dream. If that were real, every ops and finance team would already have one.
They don’t. And I don’t think the reason is just “the models aren’t good enough yet.” Even if you gave me a model with 10x better accuracy and a 10x larger context window tomorrow, I still wouldn’t hand it my bank login or payroll system and say “go wild.”
The problems I keep running into are structural:
- non-deterministic behavior
- heavy-tailed cost
- opaque failure cases
- workflows you can’t test or govern
That’s why the winning design won’t look like a computer-use agent. It’ll look like a compiler.
I’m building one version of that idea (Granite), so assume some bias. But even if you ignore the product entirely, the architecture is what matters.
The AI "co-worker."
When people say “AI coworker,” it's usually some variant of this loop:
while not done:
screen = take_screenshot(state)
next_action = llm.decide_next_action(screen)
state = desktop.do_action(next_action)
It’s impressive in isolation.
But then you run it a few more times:
- Some runs finish in a handful of steps
- Some runs spiral because the agent decides to try a new route, or a pop-up appears
- Some runs consume 10x more tokens because the agent got confused
- And for the rest, failure cases are opaque; you only realize the agent did something wrong when a human notices it.
For an enterprise, that’s a terrible combo:
- Non-deterministic costs. You can’t confidently say, “Running payroll every night will cost us about $X,” because on a Tuesday night, the agent got stuck and your token spend doubled.
- Non-deterministic behavior. Even the same prompt and environment can lead to slightly different internal reasoning, resulting in different click paths and side effects.
- Hard-to-bound risk. A junior dev might hesitate before deleting 1,000 invoices. Agents don't. We can't just say "the model usually behaves," and hope for the best.
You can add layers of protection with guardrails, approval flows, and manual reviews, but at that point, it's not much of a coworker.
What most teams actually want sounds more like:
"Please just do this boring task the same way every time. If you can't do it, then I'll take care of it."
This brings me to the pattern I keep running into.
The 95-5 pattern (and why 99.9% is not good enough)
Back-office work almost everywhere follows:
- ~95% of cases are a boring, predictable “happy path.”
- The remaining 5% are weird edge cases that require judgment.
For example, in accounting, 95% of invoice processing is boring: fields line up, the customer is known, numbers match, and dates are fine. The other 5% is where a PO doesn’t exist, or the customer is on credit hold.
Humans earn their share of that 5%.
The current “AI coworker” inverts this. We use a non-deterministic loop for the 95% that could be a program, and then ask the same loop to improvise on the messy 5%.
Assume your agent is 99.9% reliable per action (an extremely generous estimate). A realistic business workflow can easily involve 200 distinct actions (a very conservative estimate).
The probability that an entire run is perfect:
So even with 99.9% reliable steps, about 18% of runs fail somewhere.
Push it to 99.99% per step:
Now “only” 2% of runs fail. That still means 20,000 broken cases per million. That also only accounts for independent errors; real runs often have cascading failures.
That’s not “good enough.” We’ve chosen the least predictable, most expensive mechanism for the part of the work that is most amenable to being turned into a program.
Boring already works
We already have a thing that clicks through UIs in deterministic ways: RPA (UiPath, BluePrism, etc.).
It has automated huge chunks of enterprise work for years:
- Insurance claim triage
- Bank back-office tasks
- HR and payroll workflows
- Healthcare administration across terrifying legacy systems
RPA bots log into SAP, Oracle, legacy web apps, and other enterprise tools. They click the same buttons in the same order every night, and the world mostly keeps working.
Engineers hate them for good reasons. RPA is painful to build and maintain. From what I’ve seen (and done myself), it takes weeks or months of building and testing to have a complete workflow. It often requires expensive consultants who deeply understand both the business and the RPA software.
So most companies end up with:
- A short head of high-value, highly-maintained automations
- A long tail of “we really should automate this someday.”
The short head exists because determinism + predictable cost matter. The long tail exists because creating that determinism is too expensive.
The new “AI coworker” pitch basically says:
“Skip the scripting. Just let a smart agent drive the UI live.”
I think the more interesting direction is:
“Keep the determinism. Make creating it feel like a demo and not a project.”
That’s where the “compiler” mental model comes in.
From coworker to compiler
Let's redraw the workflow.
Agents as co-workers today:

But in my head, the ideal pipeline would look something like this:
- A human sits down at a VM and does the task the way they normally would
- We would record everything, including the DOM, keystrokes, etc.
- An LLM would then compile that trace into a workflow function.
- A boring worker runs that code on a schedule or via API.
- When the workflow breaks (UI change, new field), a small agent proposes a patch.
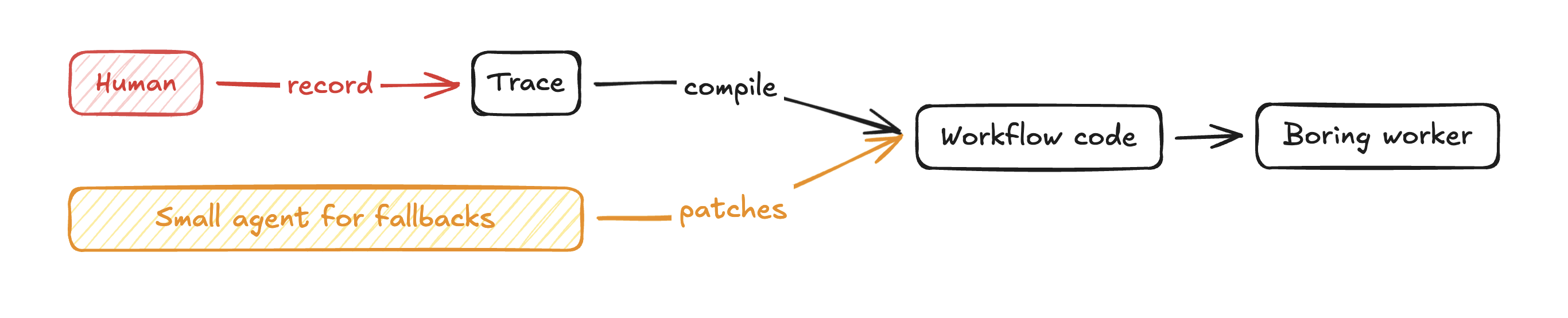
This allows the deterministic workflows to own the 95% and AI agents to carry the unexpected 5%.
Once you view the future of agentic coworkers as compilers, the enterprise applications become more reasonable. You can now:
- write tests
- smoke-test against synthetic data
- version-control behavior over time
- add invariants and assertions
- and most importantly, know exactly what will run in production
Guardrails are trivial in code, but not with agents
This is where our compiler model really earns its keep.
Let’s look at another fairly simple task of automating invoice approvals.
You want the invariant:
“If the amount changes after the user approves, abort.”
As code, this would be boring:
def approve_invoice(driver, invoice_id):
driver.open_invoice(invoice_id)
before = driver.read_amount()
driver.click("#approve-button")
driver.wait_for(".toast.approved")
after = driver.read_amount()
if after != before:
raise RuntimeError(
f"Amount changed during approval for {invoice_id}: {before} -> {after}"
)
This is trivial. If the invariant breaks, the workflow stops.
But with an end-to-end agent, you’re relying on the model to:
- notice the change
- remember the original
- understand that it’s bad
- decide to abort instead of “helpfully fixing it.”
- and do this the same way every run
You can prompt for that, but you can’t assert it with the same confidence, and that's the gap that the compiler model closes.
Where Granite fits in all of this (and where I’m biased)
I’m currently building Granite around this compiler mental model.
Right now, it works roughly like this:
You describe a manual computer task or business process in plain language. Or you sit down at a VM and do it once or twice the way you normally would inside the tool you want to automate. Granite records what happens and uses an LLM to learn how that software is being used.
Granite then creates a deterministic automation that you can parameterize and trigger via API.
It also self-heals and fails loudly, falling back to a tightly scoped agent whose job is to diagnose, propose a change, and patch the workflow. You can also choose to review those changes, gate them, or let them flow automatically.
We’re also building a memory store on top of this, so our agents can learn over time which workflows tend to fail, which repairs worked before, and which inputs correlate with which edge cases. That memory lives outside the model and gradually improves how new workflows are compiled and how failures are handled.
The long-term goal is still something that feels like a coworker. Just not one that roams freely on a desktop.
More like:
- a growing library of deterministic workflows
- the ability to suggest new workflows you could automate based on what it learns
- a constrained agent to repair and extend that library as your tools and policies change
The “AI coworker” in that world:
- runs a library of boring, tested workflows
- suggests new ones based on what you do
- wakes up a small agent to repair broken flows
If that works, then the “coworker” part shows up as orchestration using deterministic workflows as the "hands" to execute tasks and workflow suggestions to make it better.
It should be a diligent engineer who writes and tests automation but refuses to be clever in production.
And that, personally, is the coworker I'd be willing to give a login to my bank.
If you're building something similar or have feedback or opinions, I'd love to connect! Reach out to me on X or LinkedIn.